By the time 2025 is closing and the question is whether Coding LLMs/Agents/IDEs replace human programmers? gets asked,i am at ” It might actually” moment.
Few quarters before i was at “maybe let’s see”.
Thats the amount of progress state of the art has made. Based on the report you read and the date of it ,some 40 percent of code and 256 billion lines of code have been outputted by models. Forget about the impact but such numbers mean it is a large scale training and human verification that has already gone back into the models/to the labs.
With more focused optimizations from the AI LABs in the model architecture and deployments 2026, especially by plugging in some knowledge representation and knowledge priority/rankin,g might close the year 2026 on “Ah it happened”.
ps: There have been many shots taken at eliminating the programmer over the last 4 decades (really, it’s that old of a dream ). These attempts tried visuals, formatted config, drag and drop and even document based approaches. Additionally, the design based approaches like annotation and injection, also kept on happening.
But the “so called” ability to reason offered by LLMs is breaking past the totality barrier of code generation from specs. My best bet is that models becoming runtime aware is what will be the last finishing touch to the masterpiece.
Edit ,based on the feedback: Building a car and building a Ferrari that can be sold in showroom are 2 diff things . Here are links to learning resources Stanford class , Karpathy and Rashcka
LLMs have moved on since ChatGPT
As an AI Architect with production level experience with AI/Neural Networks and regular reading of various research papers in the field, the arrival of ChatGPT didn’t stun my circle of technologists as much as it did to rest of the sector.
The initial use case in generative AI was focused on using it to literally “generate” insights via prompts. It quickly morphed into a general purpose toolkit for most routine (or shallow) inferences.In a way it was sort of a Java or Windows moment for the technology field. This was the era that felt very comfortable to someone with prior hands on tensors.
The Cambrian explosion of LLMs
By the time 2024 ended, the default choice for GenAI projects wasn’t always OpenAI. There were many LLM companies that shipped many versions of LLMs with different architectural designs and sometimes shipped an internal mix of experts. In the larger field of LLMs, the scientist would still discard such differences as more differences of the same thing. But if one is crafting solutions around LLMs one has to account for differences in modality, reasoning , pure chatbots and so on. Not to forget their parameters and tasks they were specialized in ( and beat some benchmark for ) and evaluating them/output.There is also enough business traction in moving to domain-specific models . All of these demanded a personal experiential look at LLMs.
Hands-on learning of LLMs
As such, there are multiple universities and experts who have amazing courses and materials on LLMs.My search zeroed in on the course by Stanford and the material by Karpathy and Rashka.In fact, one can ask ChatGPT to generate code to create one’s own LLM and it would give you 20-something lines of code to do it . But what insight can it provide?
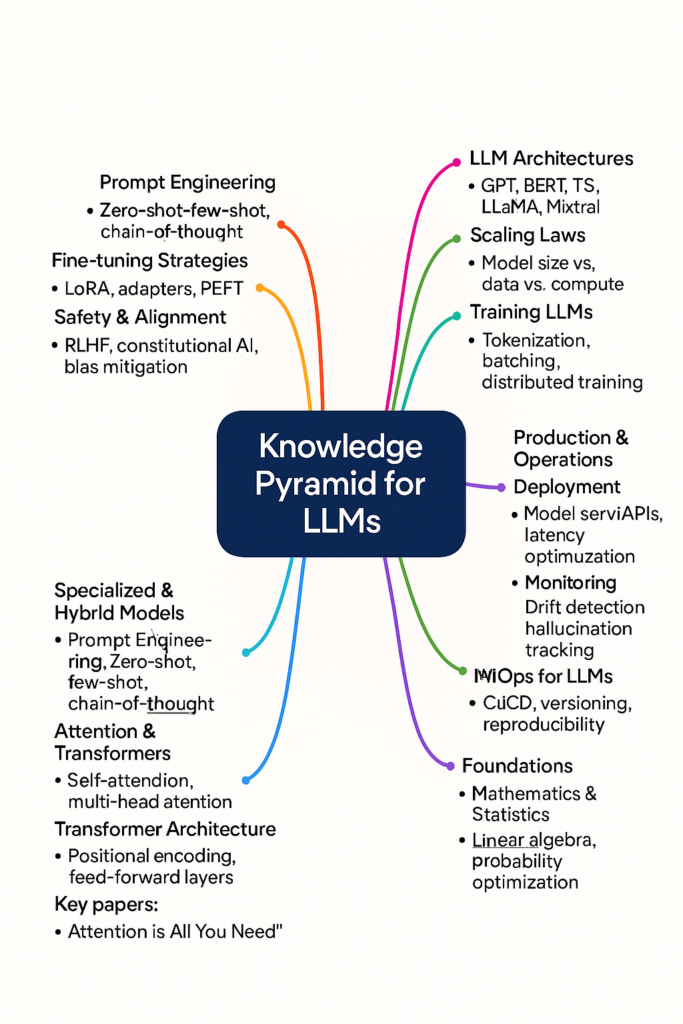
Learning path and building knowledge pyramid
This boils down to first mapping the knowledge pyramid for LLMs as a field. I got this image created with the help of ChatGPT as a reference, but one should define their own based on where he is starting and how far one has to reach (there has to be an upper end).
Another aspect of my learning approach is to read 2-3 books on the same topic. And then move to read/watch/code more along the knowledge pyramid/path. That ends up being 10-12 books or equivalent of watching/coding for each new technology wave and a few months.
As such, each book has its own objective, so when books are titled as “from scratch”, “hands on”, “head first”,” in production, or “deep dive” etc, it makes sense to read the table of contents or preface. That can give you a good idea of the journey the author will take you (and what remains for you to do on your own).It is also useful to read the book cover to cover, including the references.
For my learning style, I wanted to be guided by someone who could take the learning from a blank slate and build on it, like how the LLM state-of-the-art was built. My approach is also to type along, run and experiment. This is where Sebastian Raschka’s material on LLMs worked best for me.
Building the Actual, not a Large Language Model
Building from scratch approach meant that I had to literally start with understanding transformers, choose text and convert it into embeddings, code attention and then move on to multi-head attention while experiencing the why of it, normalize the layers and code my own GPT model. This version just allowed me to chat around the text I trained it for. But the real intention was to see how everything I did leads up to and affects the output rather than saying look, here is my LLMs”.
I then learnt to add depth by evaluating the generative output and instruction, fine-tuning it (and LoRA). This was done by downloading GPT2 and loading/using it for evaluation.I also took a detour with Ollma since I wanted to use a few mode models for evaluation and see the minute differences.
There were 2-3 variations of my model that I fine-tuned for classification and also generating my riddle version of output (remember 4th standard kids inventing their own riddle/cryptic languages for speaking, that thing).
My most fun moments were experiencing the epochs and watching the output of the print command on the model object(this is real fun, do it). The code-along approach also gave me first-hand intuition around tuning and parameters.
The most frustrating aspect, which is also a reality check, is that debugging the mistakes is very tough. Not the syntax one, but the ones related to PyTorch and the attention overlap area.
Rashka has been very generous in mentioning additional material for the curious minds. For someone like me who is looking for a wide and deep understanding of the craft, taking detours to DPO and Bahdanau attention added to the joy.
What next
Personally, I went on to spend some money on Google Colab and try it all out at a little large scale/TPUs. But that’s as far as faithful learning goes.
My friend Kamlesh has given me a target to fine-tune my post-trained LLM and beat the incumbents on one of the benchmarks :).Depends on my weekend time and budget, tough. Moreover I and Kamlesh, have a history of big ambitious aims. Last year, we wanted to build a vision model to read documents in MoDi script ( later, IITKgp took up such a project with the institution we were to approach ).
As such, there are not many corporations that will be building LLMs of their own and beat the AI labs.
The amount of data needed to give an LLM commercial meaning is bigger of a problem than server and talent cost. There is, however, a case for creating domain LL models as the optimization cycles in the field accelerate, and things become cheaper.
While I wait for the river to flow in its natural course. The most certain thing in 2026 are :
1. We shall be building a lot of agentic stuff for production.
2. …Build more solutions around LLMs
3. New LLM architectures, their specializations and runtime costs in 2026 will look far different than what we saw in the last 5 years(better, I mean).
4. You and I will be crafting commercial solutions around LLMs and AI. Something that AI labs don’t have an interest in, domain expertise and commercial standing for!
In the era before LLMs, building a conversational agent meant ….one had to literally come up with sample phrases so that the Engine could do the Named Entity Recognition. Doing this by ourselves was limiting by definition as each person would have a limited range of expression. In that era, there were also tools that generated sentences if you gave them the base activity as input.(Now that we have experienced LLMs, this sounds funny on multiple count, but it used to work). (The era before production-grade NLP was even weird, i have documented that in an earlier post . )
This is also the era when a formal framework for chatbot interaction did not exist. So we ended up building our own framework. We had to debate the fitness of different NLP libraries (Stanford vs opennlp etc) and debate about their accuracy and code framework capability around interactions/invocation. In one case i was so frustrated with NLP that i designed a framework that would allow users to issue commands instead of chat by typing and we also had autocomplete/type ahead added to it . Like how you type elaborate commands on Unix, but imagine the typing experience of Google search for this. We were able to do this with some good keyword-parser-functional paradigm. And not to forget a brilliant developer with me,Nehal . But the momentum for a formal chat-style bot was huge and frameworks arrived soon.
Designing with chatbot Frameworks
Again,a debate will unfold about the chat agent framework selection. Most of the frameworks had similar capability around the core NLP and invoking services part but they had marked differences in the “flow” aspects, voice vs text capabilities and so on . This madea huge difference when the conversions we were supporting had multiple end states or conditionalities. The implication of this statement is that when we first did our chatbot in 2014/15 , the Alexa one the field of conversation design was not acknowledged (Alexa wasn’t available in India then, we got it from us). It was a few years later, especially when the commercial use cases came along, that the User Experience of the part of the chat interaction became mainstream/part of project work (Interaction Design) . Bot discovery and interaction design are useful and important even in the agentic era.
Getting the chatbots working
Once the engine of the framework we selected and trained would determine the action, I would write and wire handlers to do the processing.It quickly evolved into a chain of command pattern cum workflow or some sort. Giving rise to all sorts of integration issues.Message transformation, Errors, Retries, Auth and so on. Some of the frameworks had built-in capability to chain conversational flows (and pass variables/values around ). Most of them had some take on retries and how long the conversation can be, but it had to be discovered than being documented.
And then there was a user.At time, he would be technically disconnect from the chatbot, so we had to maintain the whole conversation state in the database. Sometimes the follow-up step in the processing needed more inputs from the user to I had to create a local and global state for the whole interaction to be recorded.
In some use cases we had to ask the user to upload receipts, which were processed by a vision model.And guess what, the image upload and processing could take more and varied time for my chatbot to remain active.So we keep some keepalive and sweet nothing “status… updating…” going to the user,to fool the whole system. Moreover, the framework chosen didn’t have native support for this sort of outside call, so everything had to be bundled together.
In another use case, we had served him content based on a help document.This had to be done with a combination of a search index in case the document repo was too large.In case of a structured FAQ one of the engine ,NIA had built in the capability of mapping queries to document keywords (density).
As a side note , many engine had some capability to detect obscenity that sufficed.PII interestingly panned out in black and white in many cases (due to the domain and use case mix at that time).
Voice Video and Human agent handovers
The voice based chatbots had a different set of additional issues.The engines from AWS and Google had built in ability to prompt for the question again if the pronunciation wasn’t clear. At times, this ended up in multiple retries/pass at the same handler so it had to be taken care of (since not all services were idempotent ).At time, the user would totally rephrase the ask, which would throw our design off guard .
Another fun aspect is that as Alexa evolved into a voice device with screen, we suddenly had to take care of the visual aspect of the interaction. Multilingual support was out of the box, so life was cool .
Video bots were a different thing to handle. Out stuff didn’t make it to production but the idea was to emulate a human face with expressions (confidentiality etc etc).It was pretty impressive for that time .
In one of the case, we had to handover the interaction to a human agent based on the predefined scenario.It was a straightforward integration to another system with some adjustments to timeout. But when the requirement evolved into passing the whole conversation to a human agent ,we realized that we didn’t have a handle to chat interaction that is provided by the framework! So I logged them as passed it on. That eventually led us to design another product around chat interaction analysis/insights and designs and it went on to (then ) compete with chatbase product.
Some notes
When we select a new technology or framework, it’s best to adapt to its way of doing things. However, when the field is new and evolving, the capability mismatch can be huge. In many case,s when it came to call/orchestrate service calls, my experience with traditional banking development helped me handle the issues with ambiguity, state and performance better than the chatbot native generation of freshers who looked towards the state of the art for solution.It also mattered because most of the recommended remedies around these problems were to use some sort of ESB or wire RPA somehow.I had found them out of sync with spirt of chat interaction (Now that we have LLMs to reason, plan and orchestrate them, i feel validated with some sort of emotional closure) .
Later, when ChatGPT happened and we moved on to RAG and Agentic tools,it felt like I was remaking the Spiderman movie Franchise for the third time. The story from there on in next post.
As any good technologist has new “weird stuff” knocking on the door while he is focusing on some other technology. This is also the theme of how my resume got built.
Python was the first programming language I started my career with. At that time I was working on code generators,compiler switches and other “weird stuff” while my friends were working on struts and j2ee. So with much effort I moved to those technologies.Working in banking domain in mid 2000s we would create jobs to facilitate what was then called as business intelligence.These were early ancestors of data cleaning, aggregation and summarization that was done via code and service via ui. It didn’t feel amazing but it was work so we did it.
Enter ChatBots
Cut to 2009s I was obsessed with JavaScript ,Spring and whole SMAC buzz and then another “weird stuff” came my way . There we were building a chatting bot for relationship managers to support the internet banking users .I used the IBM SameTime stack while my colleagues used MS stack. Out bot could do basic chat and then allow screen sharing and video calls.
Post 2010 while I was chasing Angular ,microservices and my Ethical hacker certification, another “weird stuff” called Hadoop came along. So there I was working on MapReduce, Storm and Spark. We had do some Data Science work using Apache’s MLLib. My background with BI allowed me to work on it but converting beautiful data structures to some numbers and flags didn’t seem like calling to the programmer in me 🙂 ,so I was very happy when Data Scientist joined our team. By this time it was clear that DS was the hottest job of the decade but I had moved on to Node and Dockers of the world and then another “weird stuff” called R came along. And again i was supposed to build a chat application .I was so angry to have my “When Harry meets Sally” moment that a wrote a blog post against chatbots 🙂 (here).
ChatBots strike again
It was by this time that the role of AI-Architect was coined ,brining me peace .So I moved on to a projects working full time on AI and Automation .Our projects had working going on neural network of all kinds and all of were hands on. But industry had some other plan .A “weird stuff” called a chatbot came knocking on the door .So there I was building chatbots on multiple frameworks.We had Alexa,Google’s Dialogflow,Amazon and IBMs stacks and open source framework called RASA. Not to forget mentioning our Inhouse AI Studio/Chatbot solution called NIA that my friend GuruPrasad was developing .