Edit ,based on the feedback: Building a car and building a Ferrari that can be sold in showroom are 2 diff things . Here are links to learning resources Stanford class , Karpathy and Rashcka
LLMs have moved on since ChatGPT
As an AI Architect with production level experience with AI/Neural Networks and regular reading of various research papers in the field, the arrival of ChatGPT didn’t stun my circle of technologists as much as it did to rest of the sector.
The initial use case in generative AI was focused on using it to literally “generate” insights via prompts. It quickly morphed into a general purpose toolkit for most routine (or shallow) inferences.In a way it was sort of a Java or Windows moment for the technology field. This was the era that felt very comfortable to someone with prior hands on tensors.
The Cambrian explosion of LLMs
By the time 2024 ended, the default choice for GenAI projects wasn’t always OpenAI. There were many LLM companies that shipped many versions of LLMs with different architectural designs and sometimes shipped an internal mix of experts. In the larger field of LLMs, the scientist would still discard such differences as more differences of the same thing. But if one is crafting solutions around LLMs one has to account for differences in modality, reasoning , pure chatbots and so on. Not to forget their parameters and tasks they were specialized in ( and beat some benchmark for ) and evaluating them/output.There is also enough business traction in moving to domain-specific models . All of these demanded a personal experiential look at LLMs.
Hands-on learning of LLMs
As such, there are multiple universities and experts who have amazing courses and materials on LLMs.My search zeroed in on the course by Stanford and the material by Karpathy and Rashka.In fact, one can ask ChatGPT to generate code to create one’s own LLM and it would give you 20-something lines of code to do it . But what insight can it provide?
Learning path and building knowledge pyramid
This boils down to first mapping the knowledge pyramid for LLMs as a field. I got this image created with the help of ChatGPT as a reference, but one should define their own based on where he is starting and how far one has to reach (there has to be an upper end).
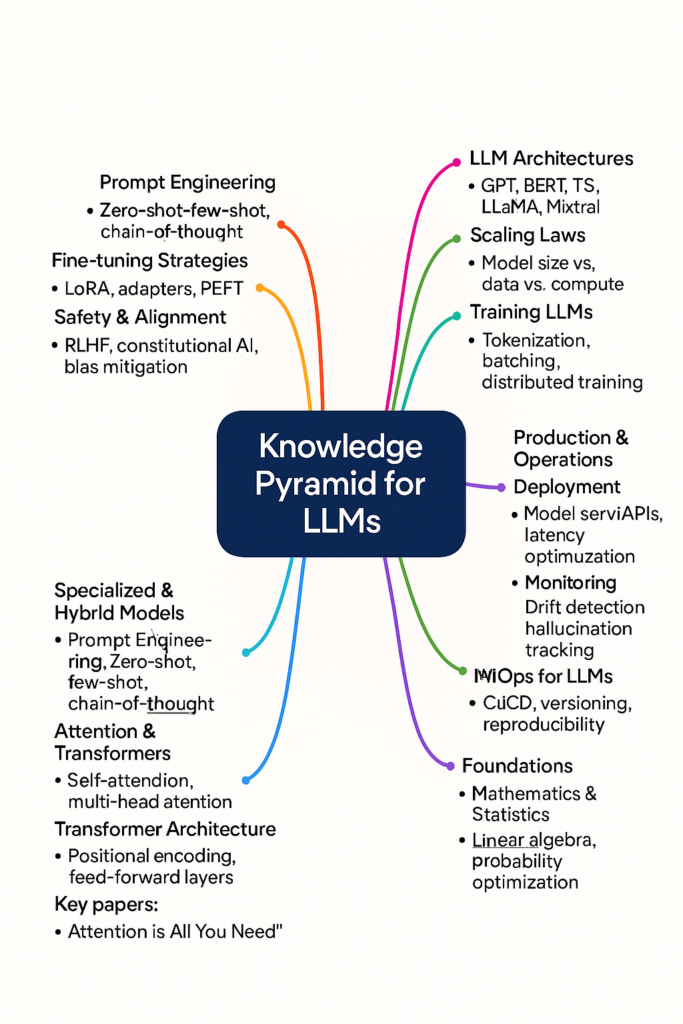
Another aspect of my learning approach is to read 2-3 books on the same topic. And then move to read/watch/code more along the knowledge pyramid/path. That ends up being 10-12 books or equivalent of watching/coding for each new technology wave and a few months.
As such, each book has its own objective, so when books are titled as “from scratch”, “hands on”, “head first”,” in production, or “deep dive” etc, it makes sense to read the table of contents or preface. That can give you a good idea of the journey the author will take you (and what remains for you to do on your own).It is also useful to read the book cover to cover, including the references.
For my learning style, I wanted to be guided by someone who could take the learning from a blank slate and build on it, like how the LLM state-of-the-art was built. My approach is also to type along, run and experiment. This is where Sebastian Raschka’s material on LLMs worked best for me.
Building the Actual, not a Large Language Model
Building from scratch approach meant that I had to literally start with understanding transformers, choose text and convert it into embeddings, code attention and then move on to multi-head attention while experiencing the why of it, normalize the layers and code my own GPT model. This version just allowed me to chat around the text I trained it for. But the real intention was to see how everything I did leads up to and affects the output rather than saying look, here is my LLMs”.
I then learnt to add depth by evaluating the generative output and instruction, fine-tuning it (and LoRA). This was done by downloading GPT2 and loading/using it for evaluation.I also took a detour with Ollma since I wanted to use a few mode models for evaluation and see the minute differences.
There were 2-3 variations of my model that I fine-tuned for classification and also generating my riddle version of output (remember 4th standard kids inventing their own riddle/cryptic languages for speaking, that thing).
My most fun moments were experiencing the epochs and watching the output of the print command on the model object(this is real fun, do it). The code-along approach also gave me first-hand intuition around tuning and parameters.
The most frustrating aspect, which is also a reality check, is that debugging the mistakes is very tough. Not the syntax one, but the ones related to PyTorch and the attention overlap area.
Rashka has been very generous in mentioning additional material for the curious minds. For someone like me who is looking for a wide and deep understanding of the craft, taking detours to DPO and Bahdanau attention added to the joy.
What next
Personally, I went on to spend some money on Google Colab and try it all out at a little large scale/TPUs. But that’s as far as faithful learning goes.
My friend Kamlesh has given me a target to fine-tune my post-trained LLM and beat the incumbents on one of the benchmarks :).Depends on my weekend time and budget, tough. Moreover I and Kamlesh, have a history of big ambitious aims. Last year, we wanted to build a vision model to read documents in MoDi script ( later, IITKgp took up such a project with the institution we were to approach ).
As such, there are not many corporations that will be building LLMs of their own and beat the AI labs.
The amount of data needed to give an LLM commercial meaning is bigger of a problem than server and talent cost. There is, however, a case for creating domain LL models as the optimization cycles in the field accelerate, and things become cheaper.
While I wait for the river to flow in its natural course. The most certain thing in 2026 are :
1. We shall be building a lot of agentic stuff for production.
2. …Build more solutions around LLMs
3. New LLM architectures, their specializations and runtime costs in 2026 will look far different than what we saw in the last 5 years(better, I mean).
4. You and I will be crafting commercial solutions around LLMs and AI. Something that AI labs don’t have an interest in, domain expertise and commercial standing for!
So the learning will continue ..